
I discovered this interesting study on arXiv about metalearning. It’s a fascinating glimpse into the future of machine learning and while I had been expecting this for a while, to finally see some solid research is amazing! The researchers evolve a bunch of convolutional neural networks using a genetic algorithm to create an optimal network for image classification. To understand what the heck I’m talking about, read on!

Let’s say that we have a collection of photographs of various animals and we want to know what is in each photo. The most basic thing we can do with the help of our own eyes, our brain and our memory is to look at a photo, see that it is of a dog and label it as “dog”. For a computer to do the very same task is an incredibly tricky process.
A couple of decades ago, computer scientists tried to identify images programmatically by building a recipe to detect individual traits and put them together to predict what the photograph depicts. For example, a dog has fur, a long nose, big eyes, a long tongue, a tail, and so on. A cat has less fur, a rounder face, smaller eyes and a flatter nose. If you find these features in the photograph, then it must be a cat/dog/kangaroo. As you might imagine, this technique barely worked at all. If a photograph was taken at a different angle, the recipe would make no sense. Each animal would need its own particular recipe to be detected, different breeds or unkempt pets would be unidentifiable and it didn’t scale very well. The technique was expensive to develop and useless in practise.

Fast forward a decade or so, and scientists tried to generalise this process a bit. Instead of detecting noses, they would detect circular shapes. Instead of fur, they would detect lines or particular patterns. Then combinations of these features would be used to be more predictive. This worked better, but it still involved manually programming in specific shapes and features to detect. It also wasn’t always successful and sometimes failed impressively as above.
Then in 1998, a completely new technique called Convolutional Neural Networks (CNNs) came out which tried to mimic how our brains process images. Instead of manually choosing features to be detected, the features would be automatically “learned” by a computer by feeding it a lot of images and the correct labels. The computer program would then calculate which features are most important and use them to classify photos. These features are basically simple mathematical filters that the image is passed through to simplify its structure into key components. By using multiple layers of features, more complex objects can be detected. Below, you can see how such a program might work. In the first layer, basic shapes are detected. In the second, these shapes are combined to build more complex ones, such as eyes and noses. And finally, in the third layer, these are combined into higher level objects, such as human faces!

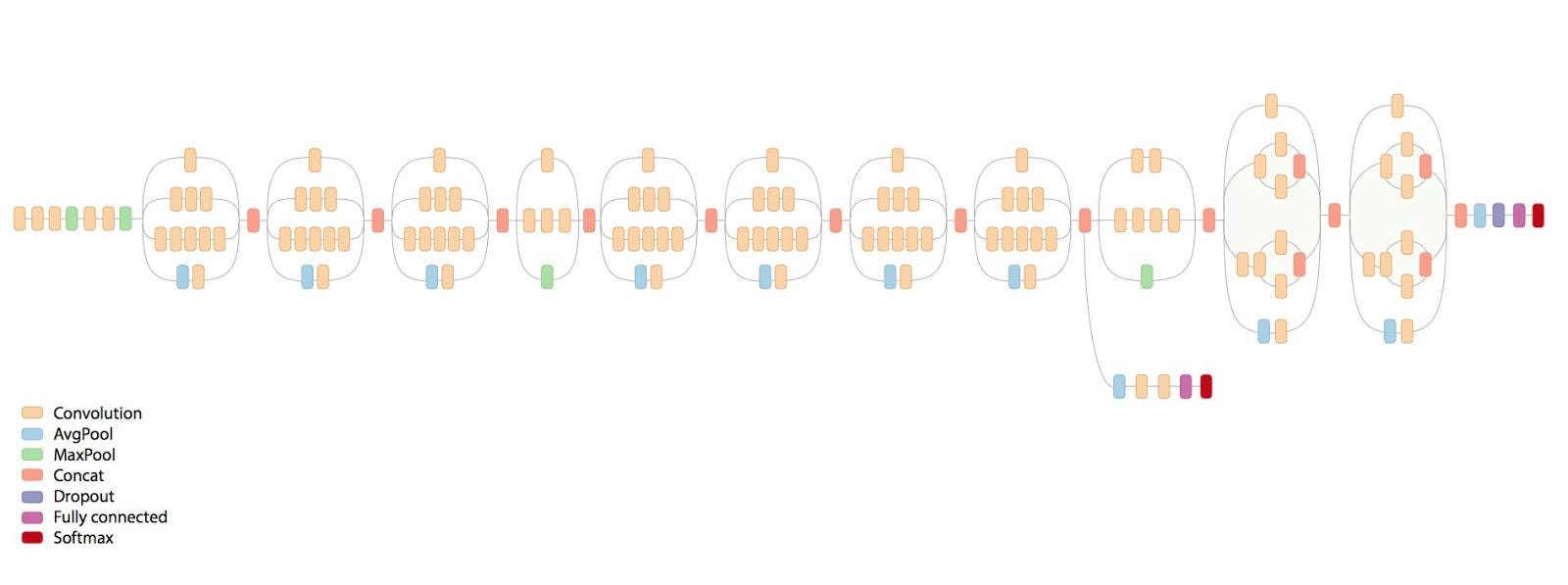
All the improvements in the last five years have been down to tweaking the neural networks slightly, either by adding new mathematical functions, changing the order and combination of filters or increasing the level of detail captured by filters. These “macroparameters” can be tweaked endlessly to get the best results but they require a bit of intuition to get right. The researchers in this paper decided to automate that last step.

Instead of tediously designing a new network and manually combining different functions and filters, they simply gave a genetic machine learning algorithm a task — to minimise the identification error — and gave it the building blocks. They then let it run for a few weeks on a fast computer. It goes ahead, builds a basic neural network and computes the error in its image recognition. It then makes a few changes, and computes a new error. If the error is lower, it adopts that design, and so on and so forth. In fact, it improves much like biological evolution, through mutation, reproduction and survival.
If you actually made it all the way to the end of this very long post, then thank you for reading! You’ll no doubt still be wondering why I find this so cool. And the reason is that not only does this paper shine a spotlight on how far we (well… brainy guys and gals) have come with artificial intelligence, but also how our world will be shaped by it in the future. We are at the point where a stupid monkey like me can play around with technology that confounded thousands of researchers for decades. Someone with a thousand pounds and no prior knowledge of artificial intelligence can achieve what took millions of research hours in the past. All we need is a data set and a clever idea and we can let AI do the hard work! I think that is both bloody impressive and quite frightening! We’re not quite there yet but there will come a point when AI will replace the computer scientists who created them so it would be wise if started planning for that future now.
In the not-too-distant future, I can imagine a scenario where anyone who wanted to make their own movie could simply write a movie script with some cues and stylistic elements, pass it to an AI who then automatically creates the soundtrack, synthesises the speech, directs a bunch of 3d generated models, adds some special effects and renders a complete photo-realistic movie. If something wasn’t quite right, you could go in and tweak it. When the film camera was invented in the 1880s, people didn’t predict how ubiquitous it would become. When the electric guitar was invented, engineers tried their hardest to remove the distortions it created, yet rock music today is built on that very sound base. I may well be wrong about the future of AI but I can’t wait to see what happens! hopefully not skynet
Further reading, if your interest is piqued:
- This fantastic talk by Andrej Karpathy, where I got most of my material from.
- A TED talk by Fei Fei Li, who established the ImageNet database
- AI experiments by Google
- Siraj Raval’s over-the-top Youtube channel
- Two Minute Papers , which showcases some of the coolest AI stuff out there!
- Chris Olah’s blog on neural networks
Animal photographs:
- Meerkats: CC-0 Mike Birdy
- Dogs & Horse: CC-0 Hilary Halliwell
- Leopard: CC-0
- Goose: CC-0
- Macaque: Public Domain
- Duck: CC-0 Martin Dickinson
- Spider: CC-by-SA Thomas Shahan
- Jaguar: CC-by-SA-ND Valerie
- Dog: CC-0 Pixabay
- Jaguar: CC-0 Skitterphoto
{kind=link}
{kind=link}
Feel free to share & modify this article under a Creative Commons Share-Alike licence and let me know if there are corrections to be made!